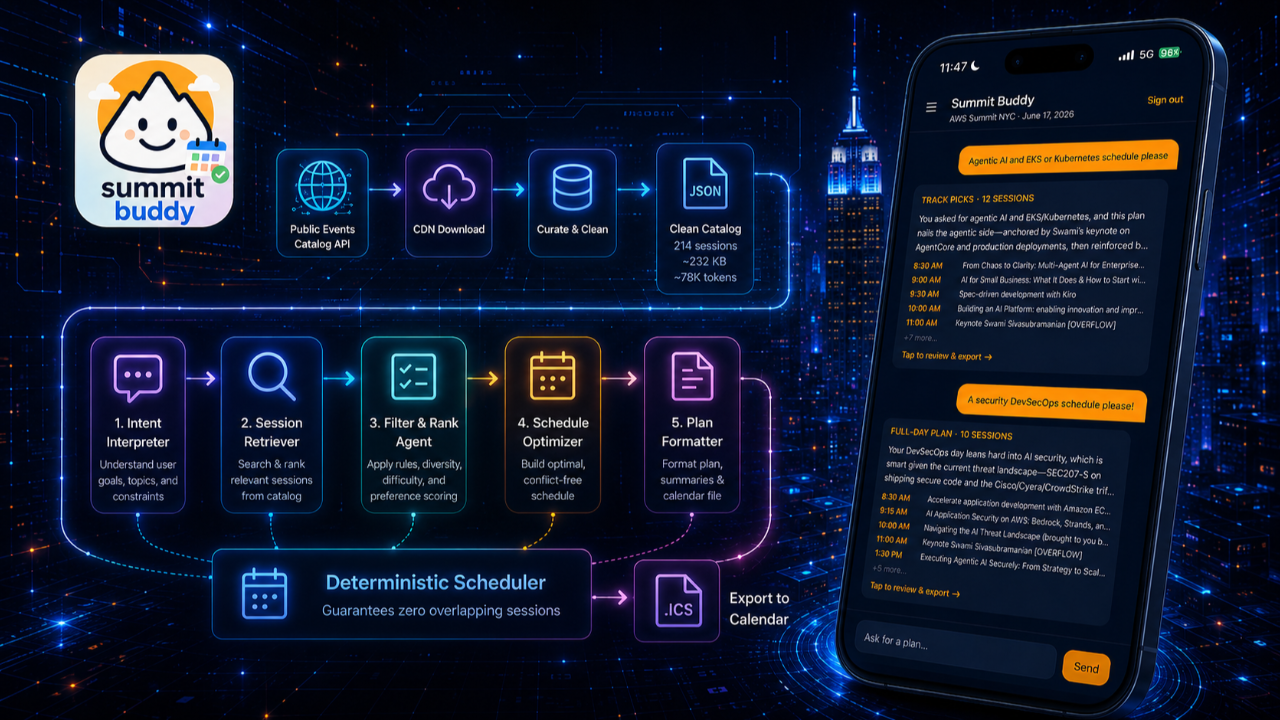
214 sessions. One day at the Javits Center. Zero time to plan it. We built an iOS app where you just chat — "fill my whole day with AI and Kubernetes talks" — and get back a personalized, conflict-free schedule you can export straight to your calendar. The app isn't the interesting part. The pipeline behind it is.
AWS NYC Summit Buddy fetches the public session catalog, curates it into a clean static artifact, and runs it through a five-agent Amazon Bedrock swarm that turns natural language into a personalized, conflict-free, calendar-ready schedule. The whole pipeline runs in-process inside a single Lambda and returns a full-day plan in about 15 seconds. Tech Stack Playbook built it to spin up multiple calendars on demand — one for the AI-heavy day, one for the security track, one for a colleague with different interests.
Below: an interactive prompt-to-calendar demo you can switch between three different requests, a click-through visualizer of all five agents, and the one architectural decision that guarantees zero overlapping sessions — every single time.
01 / THE PROBLEMTwo Hundred Sessions. One Day. Decision Paralysis.
If you've ever been to an AWS Summit, you know the feeling. You open the conference app, see 214 sessions crammed into a single day at the Javits Center, and immediately freeze. Three AI talks you want are all at 11am. Lunch disappears into a black hole. By the time you've manually pieced together a schedule, you've missed the first keynote.
The goal of Summit Buddy was never to build another agenda browser. It was to be able to spin up multiple different calendars from the same catalog — one for the AI-heavy day, one for the security track, one for a colleague with totally different interests — and let AI generate each of them in seconds instead of hand-assembling every schedule. That single requirement — many calendars, fast, from natural language — drove every decision that followed.
02 / DEMOType a Sentence. Get a Conflict-Free Day.
This is what the app actually looks like: you chat a request in natural language, and Summit Buddy comes back with a scheduled, non-overlapping plan you can review and export. Tap a prompt to see how the same catalog produces a completely different day depending on what you ask for — an AI-and-Kubernetes day, a security-track day, or a "just the next two hours" single-slot request.
Same 214-session catalog, three completely different days — and not one overlapping time slot in any of them. The "no two sessions can ever collide" guarantee isn't the AI being careful. It's a deterministic algorithm doing math the AI is deliberately kept away from. More on that in section 04.
03 / DATAThe Pipeline Nobody Talks About
Every AI product is downstream of a data pipeline. You can have the most elegant agent orchestration in the world, but if you can't get the data, you have nothing. This is the part of "AI app development" that gets glossed over in the demos — and it's where most of the real engineering lives.
The data Summit Buddy needs is the session catalog: every talk's title, abstract, speakers, room, start time, length, topic tags, and level. That data is public — AWS publishes it openly so attendees can browse the agenda before and during the event. Our pipeline simply fetches that public catalog the same anonymous, read-only way any attendee's device does, then curates it into a clean format the app can reason over. No user account, no private data, no special access — just the same list of talks anyone attending the summit can already see.
Fetch and curate, the same way everyone else does
The point was never to get at something restricted. It was to take data that's already public but trapped in a browse-one-session-at-a-time interface and pull the full catalog in one clean pass so an AI could reason over all of it at once. The output of that work is a small, dependency-free script that anyone on the team can run on demand — and the whole thing finishes end to end in about three seconds.
That little pipeline encodes a surprising number of principles that apply to any ingestion workflow:
- Find the source of truth, not a copy of it. A stripped-down web page is a copy. The structured catalog feed is the source. Always ask where the data originates and what's the cleanest public path to it.
- Handle indirection explicitly. The catalog request doesn't hand back the data directly — it returns a link to the real file, served from a CDN. Pipelines that assume "endpoint returns payload" break the moment a vendor adds a CDN hop.
- Build for drift. Public feeds change as organizers update the agenda. Each session carries a status field (
new/modified/unchanged) so you can diff catalogs and re-pull only on change. - Normalize at the edge. Some abstract fields contain stray control characters that break spreadsheet exports; custom fields are a free-form map whose shape varies per event. The curation layer cleans and defends against that before the data ever reaches the app.
- Parameterize for reuse. The same pipeline that feeds NYC feeds any other summit, just by changing the event ID.
The output is a clean, static 214-session catalog (~232 KB) that ships baked directly into the backend. No database, no vector store, no nightly refresh job. For a one-day event with a fixed agenda, that's not laziness — it's the correct architecture. The best data pipeline is the one that produces an artifact simple enough that the rest of your system gets boring.
The reason this app needs no database and no vector store is that the pipeline produces an artifact clean enough to make those things unnecessary. Most of the engineering in an "AI app" is getting the data right — not the model.
04 / THE SWARMFive Agents, Click Through Each One
You've got a clean catalog. A user types: "fill my whole day with AI and Kubernetes talks." How do you turn that into a real, conflict-free calendar — over and over, as many times as you want?
The naive answer is "one big LLM call." The problem: a single model asked to parse intent, judge relevance across 214 sessions, and do the combinatorial math of fitting non-overlapping time blocks will hallucinate overlaps every single time. LLMs are brilliant at fuzzy judgment and terrible at hard constraints. So the design principle is simple: let LLMs do what they're good at (judgment), and let code do what it's good at (math). Click any stage to see its job, its model, and why it exists.
The cheapest, fastest model handles the cheapest, fastest job: turning a sentence into structured intent. It maps casual phrasing onto a controlled vocabulary — "GenAI," "Bedrock," and "Claude" all collapse to Artificial Intelligence; "EKS," "Fargate," and "ECS" to Serverless & Containers. It also classifies the request mode (single-slot, full-day, or track-filter) and parses time windows. Using Haiku here instead of Sonnet is deliberate: intent parsing doesn't need a frontier model, and it runs on every request.
This is where the heavy reasoning happens. The researcher gets a slimmed-down view of all 214 sessions in a single context window — the catalog is small enough that no RAG or embeddings are needed — and scores every one against the user's intent on a 0–100 rubric, with bonuses for hitting all the user's topics or matching their level, and penalties for level mismatches. Crucially, it scores but does not filter or schedule. Every session comes back with a number and a one-sentence "why." Keeping its job narrow is what keeps it reliable.
The most important architectural decision in the entire app: the scheduler is deterministic code. Not an agent. Not a prompt. No model is allowed anywhere near the time math. "Fill my day with non-overlapping sessions, maximizing total relevance" is a textbook weighted-interval scheduling problem with a known optimal dynamic-programming solution — sort by end time, find the latest earlier session that fits (with a buffer), build up the best-scoring non-overlapping set, backtrack to recover the picks. This guarantees — mathematically, not probabilistically — the highest-relevance schedule with zero overlaps. An LLM can approximate this. Code proves it.
The scheduler produced the mathematically optimal plan — but "optimal by score" isn't always "optimal for a human." When two great sessions collide, which one you'd actually rather attend is a judgment call, so it's back in LLM territory. The judge only fires when conflict pairs exist, weighing human factors the raw score can't capture: direct relevance, level fit, format (a hands-on Chalk Talk over a Lightning Talk), speaker depth, even walking distance between rooms. Each decision returns a one-sentence rationale, so you see why one session won.
The last agent makes the whole thing feel human. It sanity-checks the plan for what a busy attendee actually cares about: at least 45 free minutes for lunch, bio/coffee breaks between back-to-back sessions, flags for far-apart rooms, a nudge if every pick is the same topic, and a sane energy curve (don't stack four 400-level sessions in a row). Then it writes the 2–3 sentence narrative you actually read — acknowledging your interests, highlighting the standout pick, and being honest about tradeoffs. It returns an "approved" flag that's only false if something is genuinely broken. It's the quality gate.
Why this "swarm" design wins
The pattern here isn't "use more AI." It's decompose the problem until each piece matches the right tool: a cheap model (Haiku) for parsing, a strong model (Sonnet) for judgment, and plain deterministic code for anything involving a hard constraint. The single biggest reliability win in the whole system is that the no-overlap guarantee lives in code, not in a model's good intentions. The expensive judge only runs when there's an actual conflict. And because the pipeline is fast and stateless, generating a second, third, or tenth calendar is just another prompt — exactly the multiple-calendar capability we wanted from the start.
05 / ARCHITECTUREThe Whole System, Top to Bottom
The guiding philosophy throughout: be aggressively minimal. Every component had to justify its own existence. The whole agent pipeline runs in-process inside one Lambda — no Step Functions, no orchestration framework, no message queues. For about six LLM calls, that overhead would be pure cost with zero benefit.
The AWS resources, and why each one earns its place
(Node.js 22)
Infrastructure-as-Code & CI/CD
Everything is AWS CDK v2 in TypeScript, deployed through GitHub Actions via OIDC — no long-lived AWS keys living in CI anywhere. The roles GitHub assumes hold almost no permissions themselves; they may only assume the CDK bootstrap roles that do the actual deploying. The smoke test is the favorite touch: after every deploy it requires /health to return ok and requires an unauthenticated request to return a 401 — proving in the live environment that the Auth0 layer is actually enforced, not just configured.
06 / WHY IT MATTERSThe Default Patterns Worth Stealing
Summit Buddy is a small app for a one-day conference. But the way it's built is a template for a much bigger class of problems. The contrast below is the whole lesson in one frame.
What shipped
iOS App Walkthrough
Key Outcomes
A sentence becomes a personalized, conflict-free schedule you can export straight to your calendar as an .ics file.
A weighted-interval DP guarantees the highest-relevance, zero-overlap day — mathematically, not probabilistically.
Stateless and fast, so the AI-heavy day, the security track, and a colleague's day are each just another prompt.
CDK v2 in TypeScript, GitHub Actions via OIDC, no long-lived keys, and a smoke test that proves auth is enforced live.
The Tech Stack
07 / TAKEAWAYAsk Two Questions Before You Build
The next time you're staring at a data silo or a problem that "needs AI," ask the two questions this project is built on. First: where does the data actually live, and how do I build a clean pipeline to fetch and curate it? Second: which parts of this genuinely need a model's judgment — and which parts should I refuse to let a model anywhere near?
Answer those well, and the rest of the system gets to be boring. One Lambda. A static file. A pay-per-request table. A provable guarantee where it counts and a frontier model only where judgment is genuinely required. That's not a compromise — that's the goal.
Have an AI product that needs to reason over messy real-world data?
We partner with product teams to build multi-agent systems and data pipelines that ship — Bedrock orchestration, serverless backends on AWS, and the architectural judgment to know where not to use an LLM. Things people actually use.
Book a strategy call →